
Tencent-MVSE is a large-scale benchmark dataset for the multi-modal video similarity evaluation task. The features of Tencent-MVSE includes
You can download the Tencent-MVSE dataset from here.
The folder is in the following architecture:
tencent-mvse/
├── annotations
│ ├── pairwise.json
│ ├── pairwise.tsv
│ ├── pointwise.json
│ ├── test-dev.json
│ ├── test_dev.tsv
│ ├── test-std.json
│ └── test_std.tsv
└── features
├── clip
│ ├── pairwise.zip
│ ├── pointwise_0.zip
│ ├── pointwise_1.zip
│ ├── ...
│ ├── pointwise_20.zip
│ ├── test-dev.zip
│ └── test-std.zip
├── efficientnetb3
│ └── ...
└── resnet50
└── ...
where *.json store the meta-data, *.tsv are annotation scores, and *.zip contain video features.
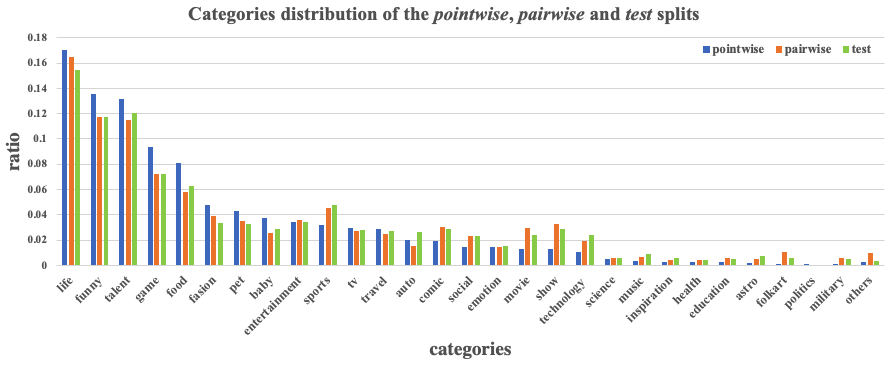
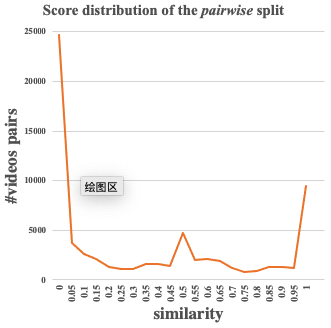
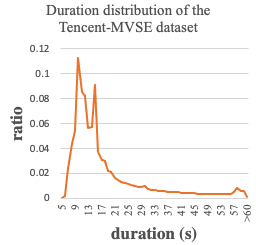
If you intend to publish results based on the Tencent-MVSE dataset, please kindly include the following reference:
@inproceedings{zeng2019tencent,
title={Tencent-MVSE: A Large-Scale Benchmark Dataset for Multi-Modal Video Similarity Evaluation},
author={Zhaoyang Zeng, Yongsheng Luo, Zhenhua Liu, Fengyun Rao, Dian Li, Weidong Guo, Zhen Wen},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2022}
}